Rezepturen spielen in vielen Bereichen der Lebensmittelchemie, Kosmetik oder chemischen Produktion eine entscheidende Rolle. Die einzelnen Bestandteile der Rezeptur ergeben zusammen mit den Prozessbedingungen in der Regel eine Vielzahl von Parametern, die sowohl die erzielte Produktqualität als auch die Kosten der Produktion erheblich beeinflussen.
Dr. Martin Kreutz
Bei der Entwicklung neuer Produkte, aber auch bei der Anpassung an variierende Rohstoffqualitäten, Betriebsbedingungen bzw. Produktmerkmale, kommt der Optimierung der verschiedenen Einflussparameter eine große Bedeutung zu. Darüber hinaus spielen im Rahmen einer Prozessoptimierung neben der richtigen Auswahl der Zutaten und Bestimmung der optimalen Prozessbedingungen auch die Qualitätskontrolle und Vorhersage von Qualitätsänderungen eine wichtige Rolle.
Ein generelles Vorgehen besteht darin, auf der Basis von Expertenwissen und durchgeführten Versuchen ein Modell für den Produktionsprozess zu konstruieren und hieraus die optimale Belegung der Einflussgrößen abzuleiten. Bei naivem Vorgehen lässt allerdings die Vielzahl der Parameter die Anzahl der notwendigen Versuche sehr schnell ansteigen. Da die Durchführung von Versuchen in aller Regel mit hohen Kosten bzw. Zeitaufwand verbunden ist, kann nur ein Teil aller möglichen Kombinationen für Belegungen der Einflussgrößen berücksichtigt werden. Das Ziel einer optimalen Versuchsplanung ist es daher, mit einer minimalen Anzahl von Versuchspunkten den maximalen Informationsgewinn in Hinblick auf die Modellbildung zu erzielen.
Hybride Modellierung mitstatistischen Verfahren und neuronalen Netzen
Bei der Konstruktion von Modellen für Produktionsprozesse werden heute vielfach Methoden aus der klassischen Versuchsplanung eingesetzt. Zu den Vorteilen sind hierbei zu zählen, dass ein systematischer Ablauf vorgegeben ist, der auf jeder Stufe eine statistische Interpretation der Zwischenergebnisse erlaubt. Allerdings werden in der Regel einfache lineare bzw. quadratische Modelle eingesetzt, die häufig sehr vereinfachte Annahmen über die Abhängigkeiten der Einfluss- und Zielgrößen sowie die Verteilung von Störungen im Prozess implizieren. Darüber hinaus bieten diese Modelle keine Möglichkeit, aus den bereits durchgeführten Versuchen neue, im Sinne des maximalen Informationsgewinns optimale, Versuchspunkte auszuwählen.
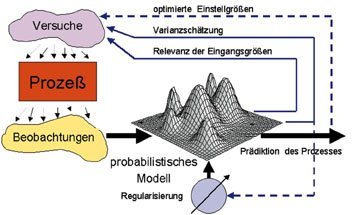
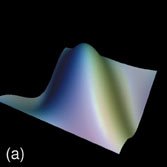
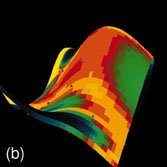
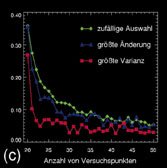
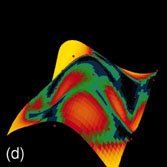
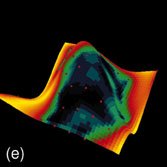
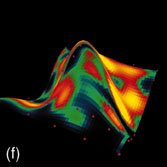
Durch den Einsatz neuronaler Modelle bzw. nichtlinearer, probabilistischer Modelle kann der starre Ablauf einer klassischen Versuchsplanung an verschiedenen Stellen aufgebrochen und erweitert werden (Abb. 1). Bereits mit wenigen Versuchen lässt sich ein initiales Modell schätzen, das Aufschluss darüber gibt, bei welchen Belegungen der Einflussgrößen die Genauigkeit des Modells am stärksten erhöht bzw. die Unsicherheit der Schätzung am stärksten reduziert werden kann. Darüber hinaus sind Aussagen über die Wichtigkeit der einzelnen Einflussparameter bzw. ihrer Abhängigkeit untereinander möglich. Lückenhafte Beobachtungen können ebenso wie vorhandenes Expertenwissen bei der Modellbildung berücksichtigt werden. Auf diese Weise werden alle Informationsquellen systematisch zusammengeführt und zur Bestimmung optimaler Versuchspunkte genutzt. Abbildung 2a zeigt dies am Beispiel einer Prozessmodellierung, bei der zur Visualisierung ein dreidimensionaler Schnitt durch zwei Einflussgrößen und eine Zielgröße durchgeführt wurde. Abbildung 2b stellt das initiale Modell mit 20 Versuchspunkten dar. In den folgenden Abbildungen ist die Anpassung des Modells nach weiteren 30 Versuchspunkten dargestellt bei zufälliger Auswahl der Punkte (Abb. 2d), bei Auswahl der Punkte, die die größte Reduktion der Unsicherheit/Varianz der Schätzung erzielen (Abb. 2e) bzw. bei Auswahl der Punkte, für die die Varianz am größten ist (Abb. 2f). Die Varianz ist in einer Falschfarbendarstellung aufsteigend von Blau nach Gelb auf der Antwortfläche des Modells aufgetragen. Die zufällige Auswahl von neuen Versuchspunkten führt zu einer deutlich schlechteren Anpassung des Modells, während die beiden anderen Methoden ähnlich zu bewerten sind. Abbildung 2c zeigt den Verlauf des Fehlers der Schätzung in Abhängigkeit von der Anzahl der Versuchspunkte. Hierbei wurde bei Auswahl der Punkte mit der größten Varianz die stärkste Reduktion des Fehlers bereits nach sehr wenigen Versuchen erzielt.
Optimierung mit evolutionären Algorithmen
Unter evolutionären Algorithmen werden stochastische Optimierungsstrategien verstanden, die auf Erkenntnissen aus der Evolutionstheorie beruhen. Sie nutzen die gerichtete Suche der Evolution, die sich im Prinzip des „Überleben des Besten“ bzw. der natürlichen Auslese ausdrückt. Evolutionäre Algorithmen operieren im Gegensatz zu anderen Optimierungsverfahren typischerweise auf einer Menge bzw. Population von Lösungen. Zur Erzeugung neuer Lösungen werden dabei Mechanismen der evolutionären Molekularbiologie wie Mutation und Rekombination in abstrahierender Form eingesetzt. Jeder Lösung wird eine Fitness zugewiesen, die die Qualität dieser Lösung widerspiegelt. Ein evolutionärer Fortschritt wird durch die sukzessive Generierung neuer Lösungen durch Variation, Bewertung und anschließende Selektion erzielt.
Evolutionäre Algorithmen zeichnen sich dadurch aus, dass sie unter komplexen Randbedingungen sehr robuste Lösungen finden können. Insbesondere bei der Schätzung von Modellen auf Basis von sehr wenigen Versuchspunkten zeigen diese Algorithmen durch ihre Robustheit ihre Stärke.
Anwendung des Verfahrens
Das hier beschriebene Verfahren basiert auf einem hybriden Ansatz von statistischen Modellen und neuronalen Netzen in Kombination mit evolutionärer Optimierung (Abb. 3). Hiermit ist es möglich, in systematischer Weise
• Modelle bereits mit sehr wenigen Versuchspunkten zu konstruieren,
• lückenhafte Beobachtungen zu nutzen,
• Expertenwissen einzubeziehen,
• neue Versuchspunkte optimal im Sinne einer Prozessoptimierung bzw. Maximierung der Modellgenauigkeit zu bestimmen,
• sehr robuste Modelle zu konstruieren und
• eine Abschätzung der statistischen Sicherheit anzugeben.
Durch Einsatz dieser Methoden lässt sich der Zeit- und Kostenaufwand sowohl bei der Entwicklung neuer Rezepturen als auch bei der Anpassung von Rezepturen aufgrund veränderter Rohstoffqualitäten erheblich reduzieren; optimale Prozessbedingungen werden schnell und sicher gefunden. Die statistische Interpretierbarkeit der Modelle ermöglicht eine sichere Bewertung der Zuverlässigkeit der Schätzung sowie der Sensitivität der Einflussgrößen.
E cav 263
Unsere Webinar-Empfehlung

Die Websession „Wasserstoff in der Chemie – Anlagen, Komponenten, Dienstleistungen“ (hier als Webcast abrufbar) zeigt technische Lösungen auf, die die Herstellung und Handhabung von Wasserstoff in der chemischen Industrie sicher machen und wirtschaftlich gestalten.
Ob effizienter…
Teilen: