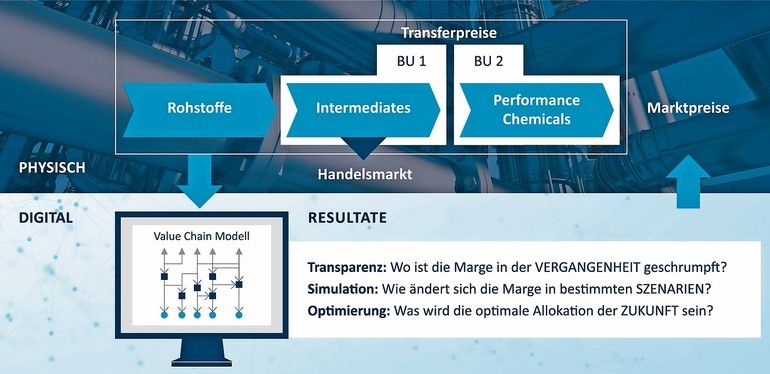
Produktionsnetzwerke sind mehrstufige Wertschöpfungsketten mit Koppelproduktionen auf einzelnen Stufen, mehreren Auslässen zum Markt, auch bei Zwischenprodukten, die sich über einen Standort erstrecken oder mehrere Standorte umfassen. Aus taktischer Perspektive sind eine Vielzahl von Allokationsentscheidungen zu treffen, z. B.
- Welche Produkte sind vorrangig zu produzieren, wenn es zu einer Verknappung des Rohstoffs (z. B. Ethylen) kommt?
- Ist es profitabler, ein Zwischenprodukt für den Handelsmarkt zu produzieren oder für den Eigenverbrauch?
- Welche Produkte sind, über die gesamte Wertschöpfungskette hinweg, überhaupt profitabel? Wie ändert sich das, wenn sich die Produktpreise oder die Rohstoffkosten um den Faktor x ändern?
Hier die richtigen Entscheidungen zu treffen, kann für die erzielbare Gesamtmarge von erheblicher Bedeutung sein. Dabei darf auch nicht vergessen werden, dass die Entscheidungsprozesse und die Aufbereitung und Interpretation der dafür notwendigen Daten heute u. U. erhebliche Ressourcen binden. Vor diesem Hintergrund sind die Anforderungen an ein IT-unterstütztes Modell:
- Schaffung von Transparenz über die erzielten Margen (Descriptive Analytics) – jedes Produkt bzw. jede Produkt-Kunden-Kombination auf jeder Wertschöpfungsstufe muss mit jedem anderen hinsichtlich der Gesamtmarge vergleichbar dargestellt werden; Gesamtmarge ist die konsolidierte Marge über die gesamte Wertschöpfungskette, d. h. unter Ausschaltung von Transferpreisen
- Simulation verschiedener entscheidungsrelevanter Szenarien (Predictive Analytics), z.B. hinsichtlich veränderter Feedstock-Preise.
- Optimierung der Allokation zur Erzielung einer maximalen Gesamtmarge (Prescriptive Analytics) unter bestimmten Annahmen (Restriktionen)
Heutige Möglichkeiten
Mithilfe bestimmter Programmiersprachen (R, Python) lassen sich heute statistische Modelle umsetzen, die gegenüber früheren IT-Lösungen deutliche Vorteile haben. Während die Programmiersprachen selbst schon über 20 Jahre alt sind, hat sich die Zahl der Programmbibliotheken seither massiv erhöht, sodass viele Komponenten vorliegen und nicht erst neu programmiert und getestet werden müssen.
Offensichtlich sind die Vorteile bei der Schnelligkeit der Entwicklung und den damit verbundenen Kosten. Der Prototyp
eines Modells für eine Wertschöpfungskette von mittlerer Komplexität kann in etwa acht Wochen erstellt werden, eine Pilotversion
in 16 bis 18 Wochen. Die Anwender sind vor allem von der Visualisierung und dem Bedienungskomfort beeindruckt.
Mängel in den zugrundeliegenden Daten (z. B. Lücken im Zeitverlauf, fehlende Daten für die Zukunft) können durch geeignete Logiken ausgeglichen werden, z. B. die
Extrapolation von Trends oder die Ableitung von Abhängigkeiten aus vorhandenen Daten. Insbesondere bei der Optimierungsfunktion eines solchen Modells kommt Künstliche Intelligenz zum Einsatz, wobei ebenso lineare wie nichtlineare Zusammenhänge modelliert und optimiert werden können.
Relevante Restriktionen festlegen
Gerade die Optimierung ist allerdings auch der erklärungsbedürftigste Teil des Modells, da sie am stärksten in die Tätigkeit von Supply-Chain-Managern oder Produktmanagern eingreift. In der Realität werden Optimierungsentscheidungen von vielfältigen Restriktionen beeinflusst: Kundenverträge mit Mindest- oder Höchstmengen, Aufnahmefähigkeit von Märkten, Knappheit an anderen Standorten, veränderte globale Warenströme usw. Hier ist es notwendig, eine Entscheidung zu treffen, welche Bedingungen in das Modell eingearbeitet werden und welche nicht. Naturgemäß kann eine vom Modell errechnete optimale Allokation immer nur eine Empfehlung sein, die noch einmal auf ihre Anwendbarkeit überprüft werden muss.
Schneller zum Ziel
Die Akzeptanz der Optimierungsfunktion hängt auch von dem Projektansatz ab, der für die Modellentwicklung gewählt wird. Ein Data-Analytics-Projekt unterscheidet sich von einem herkömmlichen IT-Projekt, bei dem auf Basis eines Pflichtenhefts ein „Tool“ erstellt wird. Es beginnt – vergleichbar mit einem Strategieprojekt – mit einer Abgrenzung und Analyse der Wertschöpfungskette, der für die betreffenden Geschäftseinheiten relevanten Strategieoptionen und Steuerungslogik und der zu unterstützenden Managementprozesse, bevor die zu modellierenden Parameter definiert werden. Die eigentliche Modellentwicklung erfolgt in einem agilen Ansatz über mehrere „Sprints“, bei denen die Anwender das Modell anhand eines Prototyps kennenlernen und Änderungs- und Verbesserungsvorschläge einbringen. Das beschleunigt die Entwicklung und vertieft das Verständnis für die Möglichkeiten und Grenzen von Data Analytics. Eine solche Entwicklung stellt hohe Anforderungen an die interdisziplinäre Zusammenarbeit aller Beteiligten (Strategieentwicklung, Supply Chain Management, Produktionsplanung, Marketing & Sales, Data Analytics, Programmierer), die eben nicht sukzessiv zum Einsatz kommen, sondern gemeinsam Entscheidungen treffen und Verantwortung für die Gestaltung des Modells übernehmen müssen.
Weitere Anwendungsfälle
Allokationsentscheidungen in Produktionsnetzwerken sind nur einer von vielen Anwendungsfällen im Bereich Value Chain Analytics, also der digitalen Steuerung von Wertschöpfungsketten. Je nach Stakeholdern und Fragestellung bieten sich weitere Einsatzgebiete an wie Pricing-Unterstützung, Gestaltung von Kundenverträgen (Formelverträge) und Budgetplanung. Es ist im Einzelfall zu entscheiden, ob unterschiedliche Belange in einem Modell abgebildet werden sollten oder ob für jede Anwendergruppe ein auf sie zugeschnittenes, separates Modell entwickelt wird (das idealerweise zumindest auf die gleichen Daten zugreift). Herkömmliche Synergieerwägungen können hier in die Irre führen. Der Aufwand für die Maßanfertigung eines Modells ist oft nur unwesentlich höher als die Anpassung eines vorhandenen Modells für einen neuen Zweck. Darin liegt gerade die Stärke der sogenannten Explorativen IT, zu der Value Chain Analytics gehört, gegenüber den bekannten der Enterprise IT, zu der z. B. ERP-Systeme gehören: die Bedürfnisse der Anwender können mit vertretbarem Aufwand wirklich punktgenau erfüllt werden.
Suchwort: cav0619camelot

Autor: Yorck Dietrich
Chemical Industry Lead, Camelot Management Consultants