
Supermärkte, Händler und Markenhersteller haben es heute mit aufgeklärten Verbrauchern zu tun, die Wert auf Qualität und Nachhaltigkeit legen. Längst geht es nicht mehr allein darum, was auf den Tisch kommt, sondern woher die Lebensmittel kommen, was sie beinhalten und wie sie verarbeitet werden. Angesichts der immer komplexeren Versorgungsketten müssen Unternehmen heute neue Technologien einsetzen, wenn sie wirklich umfassende Produktinformationen bereitstellen und die Transparenz ihrer Lieferketten sicherstellen wollen.
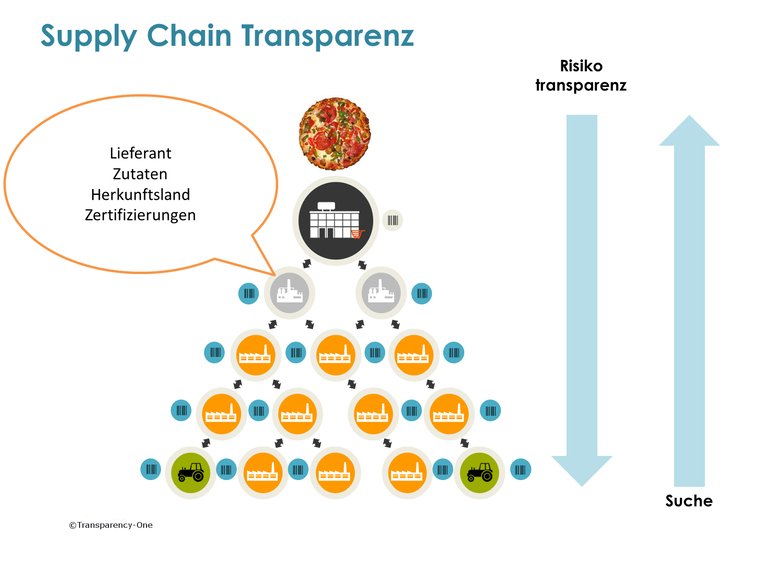
Auf den ersten Blick erscheint die Rückverfolgbarkeit von Produkten einfach, vor allem wenn die Lieferkette nur wenige Stationen zwischen Hersteller und Verbraucher umfasst. Lieferketten in der Realität sind jedoch häufig viel komplexer und erstrecken sich über eine Vielzahl an Ebenen – angefangen beim Erzeuger über verarbeitende Betriebe bis hin zum Händler, der das Endprodukt auf den Markt bringt. Je mehr Zutaten in einem Nahrungsmittel enthalten sind, desto schwieriger ist es die am fertigen Produkt beteiligten Lieferanten, Ursprungsländer oder Verarbeitungsstätten zu identifizieren. Ganz abgesehen von der Frage, ob eine Überprüfung und Zertifizierung nach lokalen Standards für die Lebensmittelsicherheit stattgefunden hat. Tatsächlich überblicken die meisten Unternehmen nur eine oder zwei Ebenen ihrer Lieferkette (Bild 1).
Transparenz als Herausforderung
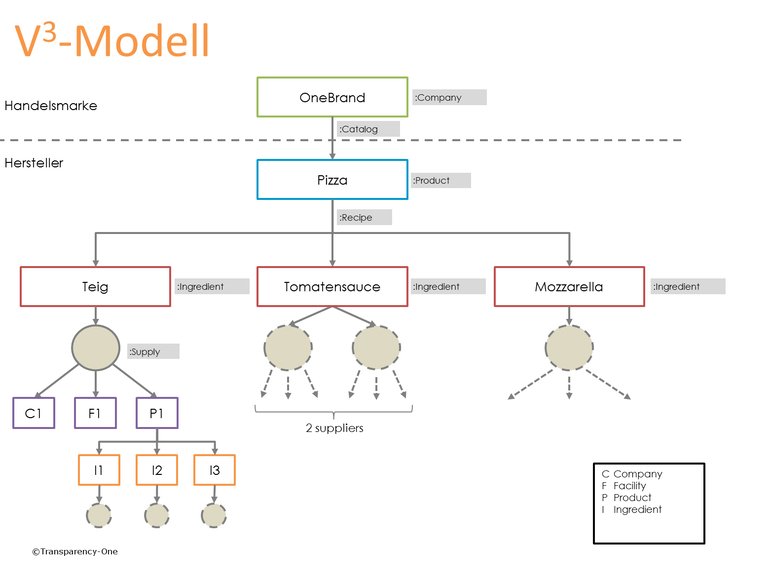
Bestes Beispiel hierfür ist die Pizza aus dem Tiefkühlregal: Die drei wichtigsten Bestandteile sind Teig, Tomatensauce und Mozzarella. Jede Zutat stammt von verschiedenen Lieferanten, die ihrerseits wieder Zutaten aus unterschiedlichen Quellen beziehen. So potenziert sich die Zahl der an der Lieferkette beteiligten Akteure schnell um ein Vielfaches.
Diese Problematik wird treffend im sogenannten „V3“ Modell veranschaulicht (Bild 2). Darin fließen drei variable Größen ein, die sich je nach Produkt und Lieferkette deutlich voneinander unterscheiden. Zunächst müssen auf jeder Ebene der Lieferkette die unterschiedlichen Zutaten berücksichtigt werden. Neben Teig, Tomatensauce und Mozzarella werden bei einer Pizza oft weitere Zutaten wie Salami, Paprika oder Pilze verwendet. Die zweite variable Größe gibt die Anzahl der Ebenen je Zutat an. Während man bei Rohprodukten wie einer Tomate schnell das Ende der Lieferkette erreicht, gestaltet sich die Rückverfolgbarkeit einer Tomatensauce aus mehreren Zutaten weitaus komplexer. Die dritte variable Größe ergibt sich aus der Zahl der Zulieferer je Zutat. Kombiniert liefern diese drei Größen Milliarden an Daten für tausende von Produkten, die erfasst und abgebildet werden müssen, um ausreichend Transparenz und Rückverfolgbarkeit zu gewährleisten.
Grenzen von SQL-Lösungen
Derart komplexe Daten bekommt man nur mit einer leistungsstarken Technologie in den Griff, die in der Lage ist, eine große Masse heterogener und komplex vernetzter Daten zu verarbeiten. Man stelle sich folgendes Szenario vor: Ein Unternehmen startet eine Rückrufaktion und muss dazu alle Produkte identifizieren, in denen Tomaten enthalten sind. Ein einfacher Suchlauf hilft hier nicht weiter, da nicht bekannt ist, auf welcher Ebene der Lieferkette gesucht werden soll. Bei einem Tomatensalat befindet sich das Rohprodukt beispielsweise auf der ersten Ebene, während es bei der Tomatensauce für Pizza auf der fünften Ebene liegt. Die Tomate könnte sogar ein Zwischenprodukt sein und gar nicht explizit als solche erwähnt werden.
Um derartige Abfragen mit SQL-Datenbanken durchzuführen, ist zunächst eine Modellierung in Tabellen und Spalten sowie komplexe (Selbst-) Verknüpfungen nötig. Verbindungen zwischen den Tabellen lassen sich nur über sogenannte Joins der Primär- und Fremdschlüssel-Tabelle berechnen. Will eine Handelsmarke etwa die Lieferkette eines Produkts zurückverfolgen, muss sie mehrere Tabellen mit Informationen zu Zutaten, Herstellern, Zwischenhändlern und Lieferanten miteinander verbinden. Bei einem großen Supermarkt mit durchschnittlich mehr als 200 000 Produkten im Sortiment entstehen so Milliarden von Knoten. Abfragen gestalten sich sehr komplex, sind zeit- und kostenaufwändig und bringen das System eher ins Stocken anstatt verlässliche Antworten zu liefern.
Komplexe Datennetzwerke als Graph
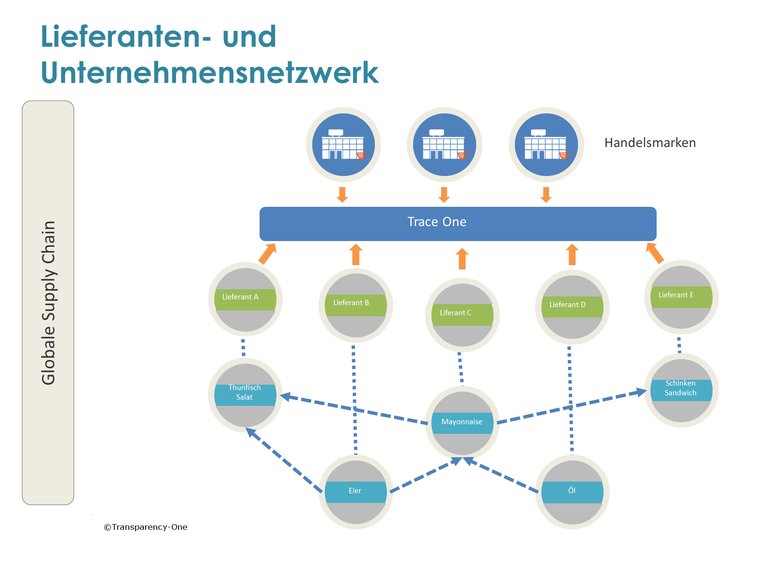
Graphdatenbanken sind dafür konzipiert, stark vernetzte und/oder unstrukturierte Informationen anschaulich darzustellen. Sie ermöglichen nicht nur mehrere lineare Verknüpfungen, sondern auch Verknüpfungen in alle Richtungen zwischen den Lieferkettenpartnern (Bild 3). Damit eignen sie sich ideal für die Analyse von Distributionswegen und schaffen einen umfangreichen semantischen Kontext, der Zusammenhänge aufzeigt und alle direkten und indirekten Nachbarn eines Produkts identifiziert.
Das Entscheidende bei diesem Modell: Beziehungen werden nicht als Metadaten behandelt werden, sondern als Objekte erster Klasse. Im Fokus stehen also nicht nur einzelne Knoten wie Zulieferer oder Hersteller, sondern auch die bestehenden Verbindungen/Kanten zwischen ihnen, z. B. die Transportwege von A nach B. Sie sind als reale Daten abfragbar und können zum Beispiel Auskunft über Tier-Klassifikation, Liefermenge oder Qualität geben. Dank leistungsstarker Suchfunktionen können Hersteller und Händler nach beliebigen Lieferanten, Zutaten oder Verarbeitungsbetrieben suchen und alle Produkte ermitteln, die innerhalb der Lieferkette betroffen sind. Diese Verknüpfung aller Partner von der Quelle bis zur Ladentheke macht Lieferketten transparent.
Schnelle Rückverfolgbarkeit
Ein weiterer Vorteil von Graphdatenbanken ist ihre Performance. Neo4j ist beispielsweise bei der Abfrage von verknüpften Daten je nach Anwendungsfall bis zu 1000-mal schneller als relationale Datenbanken. Neben der weit höheren Geschwindigkeit profitieren Anwender auch von der Möglichkeit, Daten und Strukturen problemlos zu ändern und neue Daten unterschiedlicher Art hinzuzufügen. Dies ist ein entscheidender Vorteil, da die Lebensmittelindustrie aufgrund ständig wechselnder Rezepturen äußerst dynamisch ist.
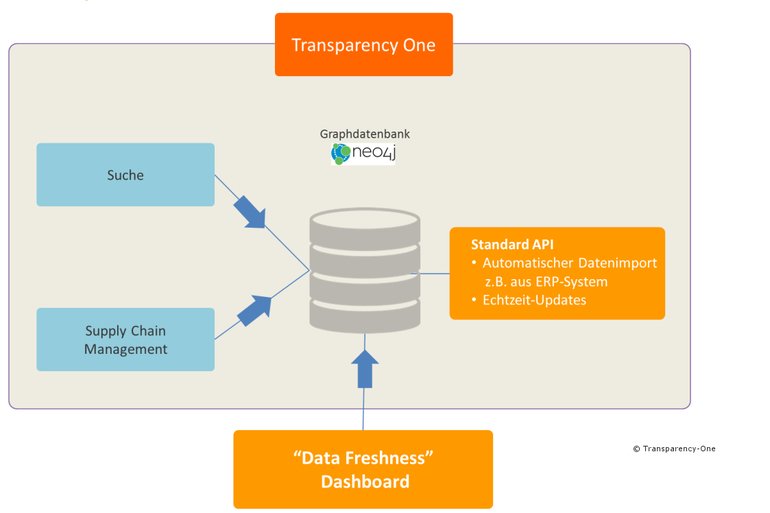
Eine Graphdatenbank lässt sich problemlos mit gängigen ERP-Systemen wie Oracle oder SAP verbinden (Bild 4). Sobald sich eine Rezeptur in der Lieferkette ändert, wird diese auch automatisch im Graphen aktualisiert. Das kann im Krisenfall der entscheidende Vorteil sein. Ob bei der Suche nach Zutaten, nach Lieferanten, nach Händlern oder nach Chargen und Sendungen: Die gewünschten Ergebnisse liegen mit hoher Genauigkeit und in Echtzeit vor. Das senkt in den Unternehmen nicht nur die Kosten und Risiken, sondern dient auch der Optimierung der Prozesse in der Logistik und gewährleistet Konformität in der gesamten Lieferkette.
So tragen Händler und Lebensmittelhersteller unter dem Strich dazu bei, das Vertrauen der Verbraucher in die Produkte zu stärken und deren Anforderungen gerecht zu werden. Dies umfasst den gesamten Qualitätsprozess, also die Verwaltung sämtlicher Daten über Zutaten, Lieferanten, Zertifikate, Rohproduktspezifikationen, Ursprungsland und landesspezifische Bestimmungen, ebenso wie die Nachverfolgung von Daten, die Etikettentreue, die Zertifizierungsstandards und die Verantwortung gegenüber der Gesellschaft. All das greift ineinander und erhöht die Transparenz und Nachverfolgbarkeit, wodurch die Lebensmittellieferkette für jeden sicherer wird.
Emil Eifrem
CEO und Mitbegründer,
Neo Technology
Teilen: