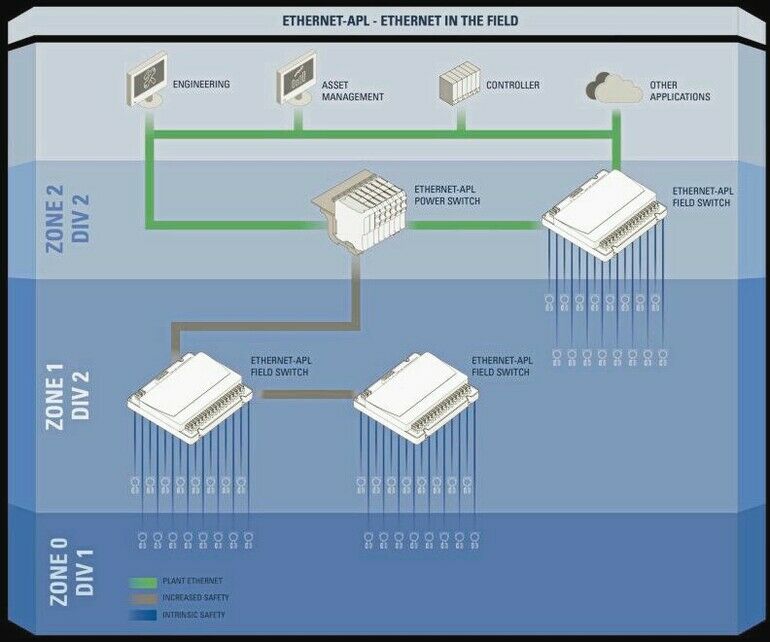
Ethernet wird schon seit Längerem in vielen Industriezweigen verwendet, dennoch werden sich Anwender in der Prozessindustrie auf neue Aufgaben einstellen müssen. Das liegt vor allem daran, dass man bei einem Netzwerkproblem bisher entweder auf die IT-Abteilung vertraute oder ein Gerät bzw. System einfach neu startete. Der Weg zur IT-Abteilung steht einem natürlich weiterhin offen, mit dem Neustart wird man sich jedoch schwertun. Und wer möchte schon bei jedem Problem beim Netzwerk-spezialisten nachfragen? Besser ist es, wenn der Anwender selbst in der Lage ist, dieses zu lösen.
Um eine Sorge gleich zu entkräften: Ein sorgsam installiertes Ethernet-APL-Netzwerk wird im Betrieb kaum Fehler verursachen, da die Technologie sehr robust ist, vorausgesetzt sie wurde korrekt installiert. Kleinere Probleme wird es jedoch – vor allem am Anfang – immer mal wieder geben. Die Fehlersuche ist in Ethernet-APL-Netzwerken viel einfacher als in klassischen Installationen, das Multimeter ist folglich nicht mehr das geeignete Instrument. In Zukunft sind diese Wege zwar nicht ganz verschlossen, aber eben keine gute Option. Daher heißt es: Alle Beteiligten werden dazulernen müssen. Ein IT-Mitarbeiter muss sich mit der Verfahrenstechnik auseinandersetzen – ein Wartungstechniker wird sich IT-Kenntnisse aneignen müssen. Entsprechende Schulungen und Maßnahmen bezüglich Qualifikationen werden derzeit von den Feldbusorganisationen entwickelt.
Intelligent Fehler erkennen
Für die Anwender wird das Leben einfacher, da Ethernet-APL zusätzliche Diagnosedaten bereitstellt. Dies bietet die Chance für Prozessoptimierungen, beispielsweise durch intelligentere Datenanalysen, indem man eine künstliche Intelligenz oder Expertenmodelle für die Diagnose einbindet. Gleichzeitig lassen sich innovative Instandhaltungskonzepte umsetzen, da die Feldgeräte unter anderem einen Wartungsbedarf einfacher und schneller selbstständig melden.
Die Diagnose bei Ethernet-APL sorgt für erhebliche Zeitersparnis. Früher musste ein Servicetechniker unter Umständen dreimal zwischen Gerät und Leitwarte hin und her wechseln. Im Feld wurde das Gerät gemessen, gegebenfalls verändert und abgewartet, ob der diagnostizierte Fehler wirklich die Ursache für den Fehler war. Nun ist eine zentrale Diagnose möglich, da man an der Engineeringstation über den Webserver beispielsweise ins Gerät schauen kann, was besonders für explosionsgefährdete Bereiche interessant ist.
Welche Fehler gibt es?
Hier muss zunächst zwischen der IP-Diagnose, also Fehlern in der Kommunikation, und der Fehlersuche auf dem Physical Layer unterschieden werden.
Typische IP-Fehler sind:
- Adresskonflikte, die durch Zahlendreher oder Mehrfachverwendung von IP-Adressen entstehen
- Kommunikationsfehler wie spontane Abbrüche oder der Versuch, immer wieder die Kommunikation (Retries etc.) aufzubauen
- aber auch ein Broadcast Storm, der zu einer Netzüberlast führen kann, entweder, weil ein Gerät defekt ist, oder es gibt tatsächlich einen Netzwerkangriff aufgrund einer DoS-Attacke
Da es sich bei Ethernet-APL um ein Standard-Ethernet handelt, stehen für die IP-Diagnose viele bereits seit Jahren bewährte Standard-Tools zur Verfügung, die teilweise sogar kostenlos sind. Diese können bis auf die Protokollebene schauen. Daher kann es sich hier in der Tat lohnen, den Kontakt zur IT-Abteilung aufzunehmen.
Fehler auf der Hardware-Seite
Mit der Diagnose des Physical Layers lassen sich folgende Fehler auf der Hardware-Seite erkennen:
- Überlast des Netzwerkes durch zu viele Teilnehmer oder zu lange Leitungen im Netzwerk
- Kabelfehler, die durch Drahtbruch oder Kurzschluss verursacht wurden. Besonders herausfordernd ist der Schirmschluss, also wenn der Kabelmantel beim Anschließen verletzt wird, da sich dieser meist erst nach einiger Zeit im Betrieb bemerkbar macht
- Dämpfung des Signals durch Kabelalterung. Um dem vorzubeugen, empfiehlt es sich, auf die Qualität der Kabel zu achten
- Störsignale, wie Rauschen, Signalverformung oder Reflektionen auf Leitungen, weisen ebenfalls auf Probleme im Netzwerk hin
- Auch Gerätefehler und Ausfälle lassen sich diagnostizieren. Daraus können sich sogar weitere Handlungsempfehlungen ableiten, etwa für ein Condition Monitoring oder Predictive Maintenance
Viele Geräte sind schon oder werden in Zukunft vermehrt mit einer internen Diagnose ausgestattet, die Vorhersagen eines Ausfalls ermöglichen. Da sich Diagnose- und Asset-Management-Daten in Echtzeit über große Entfernungen übertragen lassen, sind auch neue Konzepte wie die Namur Open Architecture (NOA) oder der Open Process Automation Standard (O-PASTM) möglich.
Bezüglich der Netzlast ist Ethernet-APL sehr robust. Um Anlagen und Prozesse in der Prozessindustrie sicher zu steuern, sollte die Netzlast idealerweise unter 10 % liegen.
Ein Blick auf die Stern-Topologie zeigt, dass bei prozesstypischen Zykluszeiten von
400 bis 500 ms selbst bei 250 Feldgeräten die Last 5 % liegt. Es sind also ausreichend Reserven vorhanden. Bei Trunk-Spur-Topologien, die in der Praxis für maximal 50 Feldgeräte ausgelegt sind, liegt die Netzlast, wenn man von gleichen Bedingungen ausgeht, sogar 1 %. Dennoch wird im Augenblick untersucht, was bei Extrembedingungen passieren kann und wie man darauf reagieren sollte.
Diagnose des Physical Layers
Bisher wurde für die Diagnose des Physical Layers die Namur-Empfehlung NE 123 (Wartung und Instandhaltung des Physical Layers von Feldbussen) herangezogen. Darin wird empfohlen, die vier Parameter Signalpegel, Rauschen, Jitter und Unsymmetrien für eine Fehlersuche und die Beurteilung des Feldbusses heranzuziehen. Überträgt man dies nun auf Ethernet-Anwendungen, stößt man an einige Grenzen. Ein Blick auf das Rauschbild eines Feldbuskabels mit 31,25 kBit/s und eines Zweidraht-Ethernet-Kabels (Voll-Duplex-Kommunikation) zeigt den Unterschied. Lediglich Experten können auf einem Ethernet-APL-Kabel beim Rauschen einen Fehler erkennen. Für die praktische Anwendung ist diese Fehlersuche wenig geeignet.
Es gibt aber einfachere Möglichkeiten: Der Vorteil von Ethernet-APL ist, dass es sich um eine Punkt-zu-Punkt-Verbindung handelt. Der Powerswitch ist also an einem Port mit genau einem Field Switch verbunden, bzw. der Field Switch ist an einem Port mit einem Feldgerät verbunden. Außerdem ist die Diagnose in Ethernet-Netzwerken längst etabliert und standardmäßig vorhanden. Dies macht die Fehlersuche bei Ethernet-APL deutlich einfacher.
Field Switches sind Diagnosezentrale
Da die Field Switches zentral im Netz sitzen, bekommen sie eigentlich alles mit, was im Netzwerk passiert. Als ganz normale Teilnehmer im Netzwerk werden Diagnoseinformationen standardmäßig beispielsweise über Profinet übertragen. Ein auftretender Fehler wird also sofort bemerkt, dies ist vor allem bei Inbetriebnahmen hilfreich.
Auf einem kleinen Display am Field Switch von R. Stahl erhält der Servicetechniker viele weitere Informationen. Außerdem ist es möglich, über einen Webserver tiefer und detaillierter in das Netzwerk und den Physical Layer zu schauen. Hier finden sich unter anderem Informationen über Spannung, Spannungspegel, Strom oder Redundanzprobleme. LEDs weisen den Weg zur Problemursache. Auf einem Diagnose-Dashboard wird in Form einer Ampel der Zustand der jeweiligen Funktionen des Geräts auf dem Trunk oder der Spur angezeigt. Eine blaue LED, die sich an der NE 107 orientiert, meldet zum Beispiel Wartungsbedarf.
Aus einer kontinuierlichen Überprüfung der Betriebs- und Umgebungsbedingungen wird weiter die zu erwartende Lebenszeit eines Field Switches berechnet. Dadurch kann eine rechtzeitige Wartungsinformation an den Operator ausgegeben werden. Daraus könnte zum Beispiel die Empfehlung für einen Gerätetausch abgeleitet werden, um Ausfälle zu vermeiden, die zu ungeplanten Abschaltungen führen.
Darüber hinaus sind zwei neue Diagnose-Parameter für die Anwender besonders interessant:
- Das SNR, Signal-to-Noise-Ratio, beurteilt die technische Qualität des Signals und informiert den Anwender, ebenfalls in Form einer Ampel, über die Netzwerkqualität.
- Der TDR (Time-Domain-Reflectory), eine Art Kabelradar, leistet ebenfalls Unterstützung. Hierbei schaut der Port ins Kabel hinein und prüft die Lauflänge und Reflexion der Kommunikationsraten. Er kann damit feststellen, ob es zu Unterbrechungen oder einer Störung wie einem Kurzschluss in der Leitung kommt. Dieses Verfahren ist sehr leistungsfähig, vor allem kann der TDR einen solchen Leitungsfehler auf 0,3 m genau lokalisieren.
Derzeit arbeiten viele Hersteller an Diagnosekonzepten für ihre Geräte. R. Stahl plant zum Beispiel die Bereitstellung von Diagnosedaten für seine Field Switches
über OPC UA in eine Cloud oder in Edge Gateways. Dies ist auch bezüglich des NOA-Konzeptes interessant. Liefert das PA DIM-Modell noch die Semantik dazu, steht eine sehr leistungsfähige Diagnose bereit.
Ethernet-APL generiert auf sehr einfache Art und Weise detaillierte Diagnosedaten und eröffnet damit vielfältige Möglichkeiten, um Fehler schneller zu erkennen und Prozesse zu verbessern. Die Herausforderung wird sein, dass die Daten auch entsprechend genutzt werden und nicht in einer Cloud verschwinden. Nutzt man jedoch die neuen Werkzeuge, steht einem unbeschwerten Betrieb mit Ethernet-APL nichts mehr im Weg.
R. Stahl Schaltgeräte GmbH, Waldenburg

Autor: André Fritsch
Produktmanager Remote I/O & Fieldbus,
R. Stahl